Statistics-Satisfaction Survey
>
library(agricolae)
> library(RODBC)
> setwd("E:")
> canal <- odbcConnectExcel("satisfaction.xls")
> T1<-
sqlFetch(canal,"tema1")
> T2<-
sqlFetch(canal,"tema2")
>
T3<-
sqlFetch(canal,"tema3")
>
T4<-
sqlFetch(canal,"tema4")
> odbcCloseAll()
> # T1: P1,
P11, P12, P15, P18, P19, P20, P21
> # P18 Genero
>
total<-table(T1[,6])
> P18<-
round(total*100/sum(total),0)
>
P18
Mujer Varón
17 83
> # P20 Grados
>
total<-table(T1[,8])
> P20<-
round(total*100/sum(total),0)
> # P21
Ocupación
>
total<-table(T1[,9])
> P21<-
round(total*100/sum(total),0)
> # P19 Edad
>
P19<-na.omit(T1[,7])
> clases<-c(20,35,50,65)
> h<-
graph.freq(P19,breaks=clases,plot=F)
> table.freq(h)
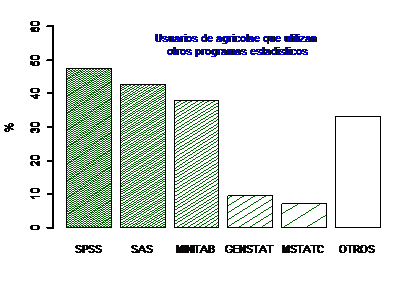
> # P17, tema 4 Otros
programas estadísticos, FIGURA 4.2
>
x<-sort(table(T4[,2]),decreasing = TRUE)
>
P17<-round(c(x[1:5],OTROS=sum(x[-(1:5)]))*100/42,1)
> par(mar=c(4,4,2,0),cex=0.7)
>
x<-barplot(P17,density=c(30,24,16,8,4,0), col=colors()[81], lwd=2, ylim=c(0,60),
ylab="%")
>
text(4,55,"Usuarios de agricolae que utilizan\n otros programas
estadisticos",col="blue")
> # Especialidad
>
total<-table(T1[,10])
>
especialidad<- round(total*100/sum(total),0)
Tipo de usuarios más frecuentes
Según la especialidad, grado académico, ocupación, edad, tipos de programa que utilizan y la institución donde trabajan, presentaron la siguiente distribución de frecuencia:
Por especialidad
Forestales Estadísticos Agrónomos Biólogos Genetistas Otros
12(25%) 11(23%) 9(19%) 4(8%) (2%) 11(23%)
Por grado académico
PhD Maestría Graduado
11(23%) 30(62%) 7(15%)
Por ocupación:
Investigador Docente Estudiante
32(67%) 7(15%) 9(19%)
Por tipo de programa estadístico
Según la encuesta, los software más utilizados son SPSS, SAS y MINITAB, como se muestra en la figura 4.2. Más del 30% de usuarios utiliza al menos uno de estos programas.
Figura 4.2. Uso de otros programas
Por edad.
Inf Sup MC fi fri Fi Fri
20 35 27.5 20 0.4166667 20 0.4166667
35 50 42.5 12 0.2500000 32 0.6666667
50 65 57.5 16 0.3333333 48 1.0000000
Instituciones con mayor número de encuestas enviadas:
- Universidad Nacional Agraria La-Molina (19)
- International Potato Center (8)
- INIA- Peru (5)
Otras instituciones con menor número de encuestas (16):
-
University of Copenhagen - Dinamarca
-
Warsaw University of Life Sciences - Polonia
-
ARVALIS - Institut du Végétal – Francia
-
ITB – Institut technique de la betterave – Francia
-
Department Earth and Environmental Sciences, K.U.Leuven- Belgica
-
Chinese Academy of Science the Institute of Botany - China
-
Government of Canada - Canada
-
ICRISAT - India
-
Ind Inst of Hort Research, Bangalore - India
- IRRI – Filipinas
- Universidade do Estado de Santa Catarina - Brasil
- Edumetrics Cía. Ltda - Ecuador
- MINAG - Perú
- Universidad Nacional San Antonio Abad-Cusco - Perú
- Universidad Nacional Altiplano – Perú
P1.- ¿Cuánto tiempo hace que utiliza la librería AGRICOLAE?
>
total<-table(T1[,2])
> P1<-
round(total*100/sum(total),0)
>
par(mar=c(0,0,0,0),cex=0.9)
>
pie(P1,density=c(0,4,8,16), col=c(1,2,3,4))
>
legend("topright",title="Meses %",paste(names(P1)," : ",as.numeric(P1),sep=""))
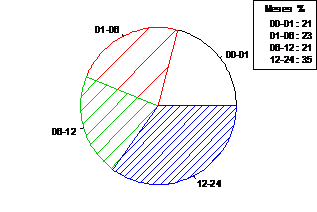
Figura 4.3. Distribución de los usuarios según la antigüedad del uso de
agricolae
Análisis de satisfacción.
Análisis de frecuencia por tipo de función de agricolae.
Se aplicó el siguiente procedimiento en R para obtener los resultados por tipo
de función.
>
# Tema 2, P2 y P3
>
# Escala de 0 a 1
> E3
<- -0.25+0.25*T2[,3]
> P3
<- tapply.stat(E3,T2[,2], mean)
>
V3 <- tapply.stat(E3,T2[,2], var)
>
N3 <- tapply.stat(E3,T2[,2],length)
> tabla<-
cbind(round(table(T2[,2])*100/45,1),round(P3[,2],2))
>
tabla<-data.frame(tabla,n= N3[,2],var=V3[,2])
>
tabla <- tabla[-5,]
>
# ordenando
>
tabla <- tabla[order(tabla[,1]),]
>
colnames(tabla)<-c("%", "Escala", "n", "var")
>
par(mar=c(4,12,2,2),cex=0.8)
>
x<-barplot(tabla[,1],las=2,horiz=T,density=6,xlab="%
de uso",xlim=c(0,100), names.arg = rownames(tabla),col= "blue")
>
text(cbind(tabla[,1]+8,x),paste(as.numeric(tabla[,2])))
>
title(main="Agricolae: % uso y satistacción de las funciones\nEscala 0-1")
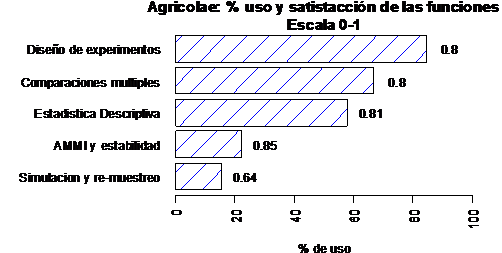
Figura 4.4. Satisfacción del uso de funciones de agricolae
Tabla 4.10
Satisfacción del uso de funciones y sus estadisticas.
% Escala n var
Simulacion y re-muestreo 15.6 0.64 7 0.01785714
AMMI y estabilidad 22.2 0.85 10
0.03055556
Estadistica Descriptiva 57.8 0.81 26 0.03653846
Comparaciones multiples 66.7 0.80 30 0.04482759
Diseño de experimentos 84.4 0.80 38 0.02080370
Según la figura 4.4 y la tabla 4.10, los tipos de funciones más utilizados fueron: “Diseño Experimental”, con 84.4%, y “comparaciones múltiples” con 66.7%. Respecto a la calificación en la escala de 0 – 1, las funciones de estabilidad alcanzan el nivel 0.85, siendo el más alto según la escala 0-1. Otras funciones presentan puntajes mayores a 0.75, siendo catalogadas como muy buenas, y el tipo “simulación y re-muestreo”, como bueno.
Según la prueba de t-student para la media de la escala en “comparaciones múltiples” bajo la hipótesis alterna mayor de 0.5 resulto. así:
T calc. = (0.8-0.5) /sqrt(0.04482/30) = 7.76, p.valor = 7.37e-09
De igual forma para las medias de los otros tipos según el número de respuestas se encontró p.valores como:
Diseño de experimentos: 1.17 e-15
Estadística descriptiva: 2.43 e-08
Estadísticamente los niveles de escala son superiores a 0.5, dando una satisfacción muy buena para los tipos de función.
Análisis de las preguntas de satisfacción del usuario dado por las preguntas de
la encuesta P4, P5, P6, P12 y P15, según la escala de Likert.
> #
Tema 3: likert P 4-5-6-12-15
> A<-T3[,c(2:20,26:27)]
> rownames(A)<-T3[,1]
La matriz original tiene 48 filas y 21 columnas.
Promedios por ítem, para puntajes entre 1 y 5:
> round(mean(A,na.rm=T),1)
P4_1 P4_2 P4_3 P4_4 P4_5 P4_6 P4_7 P5_1
P5_2 P5_3 P5_4
4.2
4.3 4.2 4.4 4.0 3.8 4.0 4.4 4.2 4.5 4.1
P5_5 P5_6
P5_7 P6_1 P6_2 P6_3 P6_4 P6_5 P12 P15
3.7
4.4 4.3 4.4 4.2 3.9 3.7 4.0 4.8 4.7
El puntaje más bajo fue 3.7 para P5_5 “Conocimiento de agricultura” y P6_4 “Agricolae es fácil de usar”, y el más alto, 4.8, para P12 “Usará agricolae en el futuro”.
Puntaje total por ítems:
> sum(A,na.rm=T)
[1] 4076
El puntaje total máximo esperado: (48)( 21)(5) = 5040
El factor de calidad es: 4076/5040 = 0.8087
Evaluación de los ítems.
Para la evaluación de los items se elimina las filas con celdas vacías,
resultando 39 filas (encuestas):
> A<-na.omit(A)
La nueva matriz completa es de 21 variables: "P4_1" "P4_2" "P4_3" "P4_4" "P4_5" "P4_6" "P4_7", "P5_1" "P5_2" "P5_3" "P5_4" "P5_5" , "P5_6" "P5_7" , P6: "P6_1" "P6_2" "P6_3" "P6_4" "P6_5", “P12” y "P15"
Con la matriz se calcula el puntaje total, sus límites de confianza, la correlación de spearman de cada variable con el total, y el coeficiente de Cronbach.
Estimación del límite de confianza del puntaje total de satisfacción
Según el número de ítems, se espera un puntaje promedio de (21+105)/2 = 63. Según la encuesta:
>
unos
<-
rep(1,ncol(A))
>
suma<-
as.matrix(A)%*%unos
>
n<-
nrow(A)
>
media
<-
mean(suma)
>
pos1<-1*21
>
pos5<-5*21
>
esperado
<-
(pos1+pos5)/2
>
sdprom
<-
sd(suma)/sqrt(n)
>
Linf
<-
media - 1.96*sdprom
> Lsup
<-
media + 1.96*sdprom
El promedio es 87.53 y su desviación estándar, 1.3759; entonces sus límites de
confianza son < 84.8 ; 90.2 >
El intervalo de confianza está por encima del valor esperado (63),
por lo tanto es satisfactorio a favor de la calidad.
Cálculo de la correlación de spearman y la determinación de las variables más
importantes para la satisfacción de los diferentes tipos de función
> correlacion
<-
cor(A,suma,method=
"spearman")
Con los puntajes totales se separa dos grupos: el 25% superior y el 25% inferior
de las encuestas, y se calcula las diferencias entre los promedios para cada
ítem (pregunta de la encuesta). Para esto, se utiliza los cuantiles del tipo 6
que son los cuantiles estándar para los programas SAS, SPSS y MINITAB.
>
maximos<-A[suma>quantile(suma,0.75,type=6),]
>
minimos<-A[suma<quantile(suma,0.25,type=6),]
>
diferencia
<-
mean(maximos)-mean(minimos)
> puntajes<-
-0.25+0.25*mean(A)
Con las diferencias, las correlaciones y los puntajes se forma una nueva tabla
para escoger los ítems de máxima diferencia y correlación alta.
>
B<-
data.frame(diferencia, correlacion, puntajes)
> B<-round(B,4)
La tabla del objeto B tiene el siguiente contenido
> B
diferencia correlacion puntajes
P4_1 1.1528 0.7422 0.7949
P4_2 0.9167 0.5999 0.8013
P4_3 1.3056 0.6478 0.7949
P4_4 1.1528 0.5778 0.8526
P4_5 1.1528 0.4606 0.7628
P4_6 0.6250 0.3715 0.6987
P4_7 1.3194 0.5895 0.7500
P5_1 0.6389 0.3164 0.8397
P5_2 0.9306 0.3365 0.7885
P5_3 0.5417 0.2830 0.8590
P5_4 0.8333 0.4475 0.7756
P5_5 1.1667 0.4208 0.6731
P5_6 0.7778 0.5118 0.8397
P5_7 0.8056 0.4139 0.8013
P6_1 1.0139 0.6068 0.8526
P6_2 1.3889 0.7627 0.7756
P6_3 1.5694 0.5247 0.7179
P6_4 2.4167 0.7559 0.6667
P6_5 1.5278 0.7511 0.7308
P12 0.6250 0.5153 0.9423
P15 0.7500 0.5366 0.9167
En la tabla B se debe seleccionar el conjunto de variables que tienen las
máximas diferencias y las más altas correlaciones. El criterio es:
-
Las diferencias mayores que sean superiores a la mediana de las diferencias.
-
Las correlaciones mayores a 0.60.
Con estos criterios se tiene dos conjuntos selectos:
> selecto1<-B[B[,1]>
quantile(B[,1],0.5,type=6),]
>
selecto2<-
B[B[,2]>0.6,]
> selecto1
diferencia correlacion puntajes
P4_1 1.1528 0.7338
0.7949
P4_3 1.3056 0.6983
0.7949
P4_4 1.1528 0.6825
0.8526
P4_5 1.1528 0.4314
0.7628
P4_7 1.3194 0.6897
0.7500
P5_5 1.1667 0.3927
0.6731
P6_2 1.3889 0.7145
0.7756
P6_3 1.5694 0.6123
0.7179
P6_4 2.4167 0.7876
0.6667
P6_5 1.5278 0.7358 0.7308
> selecto2
diferencia correlacion puntajes
P4_1 1.1528 0.7422 0.7949
P4_3 1.3056 0.6478 0.7949
P6_1 1.0139 0.6068 0.8526
P6_2 1.3889 0.7627 0.7756
P6_4 2.4167 0.7559 0.6667
P6_5 1.5278 0.7511 0.7308
La intersección de ambos conjuntos conforma los ítems que mejor miden el nivel
de satisfacción del usuario según los criterios de la escala de Likert:
> selecto
<-
selecto1[rownames(selecto1)%in%rownames(selecto2),]
> selecto[order(selecto[,3],decreasing=T),]
diferencia correlacion puntajes
P4_1 1.1528 0.7422 0.7949
P4_3 1.3056 0.6478 0.7949
P6_2 1.3889 0.7627 0.7756
P6_5 1.5278 0.7511 0.7308
P6_4 2.4167 0.7559 0.6667
Estas variables en orden de importancia corresponden a:
P4_1 Satisfecho con la calidad
P4_3 Integración con R
P6_2 Agricolae hace lo que dice
P6_5 Agricolae es competitivo
P6_4 Agricolae es fácil de usar
mean(selecto)
diferencia correlacion puntajes
1.55836 0.73194 0.75258
El promedio 0.752 es superior a 0.75 según la escala de 0-1, la satisfacción del usuario respecto del software es muy buena.
Estimación del índice alfa de Cronbach (α)
> V<-diag(var(A))
> S<-var(suma)
> alpha <- (21/20)*(1 - sum(V)/S)
> alpha
El valor estimado de α es 0.88. Como es superior a 0.80, el instrumento para medir la satisfacción de la librería agricolae es fiable.
Análisis de las preguntas de satisfacción del usuario respecto a otros programas estadísticos (preguntas 11, 12 y 15 de la encuesta)
P11.- Piense en productos similares ofrecidos por otros programas
estadísticos, ¿cómo comparar los procedimientos ofrecidos por agricolae dentro
del programa R?
>
par(mar=c(6,4,2,2))
>
total<-table(T1[,3])
> P11<-
round(total*100/sum(total),0)
>
barplot(c(P11[4],P11[-4]),density=c(8,16,24,32,0), col=2:5, ylim=c(0,50),
ylab="%",
main="Funciones de agricolae\nversus otros programas similares",las=2)
Según la figura
4.5, más del 40% considera mejor a los productos ofrecidos por agricolae dentro
de R.
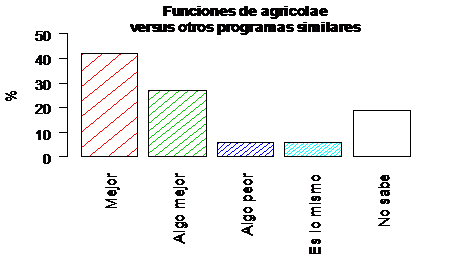
Figura 4.5. Comparación con otros software para las funciones de agricolae
P12.-¿Usaría agricolae en el futuro?
>
total<-table(T1[,4])
> P12<-
sort(round(total*100/sum(total),0) , decreasing=T)
>
par(mar=c(2,4,1,0),cex=0.85)
>
barplot(P12,col=colors()[c(91,21,1)], ylim=c(0,100), ylab="%")
>
text(2,95,"¿Usaria agricolae en el futuro?")
Según la opinión de los encuestados, el 80% definitivamente seguirá usando la
librería agricolae y sólo un 4% no está seguro. Ver la figura 4.6.
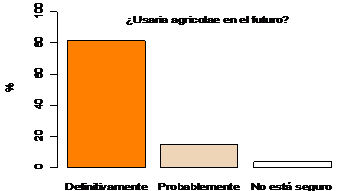
Figura 4.6. Potencial de usuarios de agricolae
P15.- ¿Recomendaría usar agricolae a los colegas o contactos de su institución?
>
total<-table(T1[,5])
> P15<-
round(total*100/sum(total),0)
>
par(mar=c(2,4,2,2),cex=0.9)
> barplot(P15,
col=colors()[c(81,16)], ylim=c(0,100), ylab="%")
>
text(1.5,90,"¿Recomendaría usar agricolae\na colegas o contactos de su
institución?")
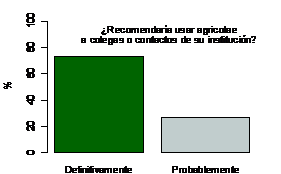
Fig. 4.7. Porcentaje de encuestados que recomiendan el uso
Según la figura 4.7, más del 60% de usuarios de agricolae recomendaría el programa a otros.
4.2.9 OPINIÓN DE ENCUESTADOS
P8: ¿Qué le gusta de la librería agricolae?
Es funcional, amigable, versátil, bastante útil, rapida en el proceso, novedosa, y provee soluciones estadísticas que otros paquetes no disponen. Es exclusiva para la agricultura, ademas libre y con practicidad y contenido.
P9.-¿Qué le disgusta de la librería agricolae?
Proporciona poca información sobre los datos de ejemplo; el inicio es dificultoso, algunas veces; requiere de muchos comandos, y la forma de los datos para usar las funciones, así como la forma de presentar sus resultados son complejas.
P10.- ¿Qué funciones le gustaría que incorpore agricolae en el futuro?
Estadística espacial, climatodiagrama, biodiversidad, estabilidad fenotípica ( Eberhart and Russell), econométricas, redes neuronales.
P13.- ¿Por qué no usaría agricolae en el futuro?
Porque existen otros software más simples; a agricolae le falta funciones para microarrays, por lo complicado, además de ser compleja en su uso. Si deja de ser libre, requiere de mucha dedicación.
P14.- ¿Por qué usaría agricolae en el futuro?
Porque se actualiza, es gratuito, tiene elementos más amigables y versátiles que otros sofware. Tiene funciones que yo necesito, es competitivo, rápido, y de aplicación práctica, en sus resultados.
P16.- ¿Por qué no recomendar agricolae?
Por conocimiento del R; por la dedicación, requiere de mucho tiempo para familiarizarse. No hay razon por no recomendarlo.
4.2.10 OPINIÓN DE EXPERTOS
P8 - ¿Qué le gusta de la librería agricolae?
Es un paquete de conceptos para la agricultura, con diseños experimentales, tratamiento de Genotipo*ambiente, facilidad de uso, e importante para la mejora de la investigación de cultivos en los países en desarrollo sin acceso a costosos programas. Ahora se puede añadir los experimentos de campos al open office y R; presenta una comparación múltiple paramétrica así como no paramétrica; existe un ahorro de tiempo al hacer el análisis de los datos; hay buenos resultados; y el apoyo a través de la respuesta es excelente.
P9 - ¿Qué le disgusta de la librería agricolae?
El redondeo de decimales; la estimación de parámetros debe darse en un número suficiente de decimales sobre todo si estos valores se pueden utilizar en otros cálculos; no se puede guardar los resultados en un objeto; un diseño alfa bueno resulta dificil de analizar; la idea de presentar los diseños, por ejemplo, dado por Cochran y Cox es buena, pero también, se debe mostrar la forma de analizarlos. Ladescripción de los datos es mala; las funciones deben ser mejor explicadas. El usuario sin conocimientos profundos sobre los temas correspondientes puede tener problemas en la comprensión de las funciones. La sintaxis en la descripción es compleja. Según mi uso agricolae es bueno, Es muy importante tener tan encuenta el análisis dialélico es tan importante como LxT para un mejorador.
P10 - ¿Qué funciones le gustaría que incorpore agricolae en el futuro?
Análisis de modelos mixtos, análisis espacial, de medidas repetidas, comparación de medias y accesorios con diferentes estructuras de varianza-covarianza, diseños desequilibrados (multi-entorno, ensayos para comparar diversas variedades), medias ajustadas, prueba de Newman-Keuls, mezcla de modelos especialmente para la serie de experimentos y parcelas divididas, utilizar algunos procedimientos del paquete SASmixed para analizar los datos, experimentos dialelicos, cartografía genética y fuerte análisis de QTL (MI, CIM y MIM).
P13 - ¿Por qué no usaría agricolae en el futuro?
Porque no todo lo que necesito se encuentra en el paquete. No se incluye algunos análisis.
P14 - ¿Por qué usaria agricolae en el futuro?
Por lo fácil de usar; hay muchas funciones en el mismo paquete; existe una posible mejora en cada versión; hay énfasis en la experimentación agrícola. Esto es muy importante para mí. Es libre uso.
P16 - ¿Por qué no recomendaría el uso de Agricolae?
Porque no todo el mundo está familiarizado con R.
4.2.11 PUNTAJE DE LAS RESPUESTAS DE EXPERTOS Y OTROS SEGÚN LAS VARIABLES IDENTIFICADAS PARA MEDIR LA CALIDAD
Expertos:
>
filas<-c(39,32,43,42,31,33,45,41,46,47,48)
>
columnas<-c(19,20,2,17,4)
> T3[filas, columnas]
P6_4 P6_5 P4_1 P6_2 P4_3
39 3 4 4 5 5
32 3 3 3 3 3
43 5 4 5 4 5
42 5 4 4 5 4
31 4 4 4 5 4
33 4 4 4 4 5
45 3 5 5 5 5
41 4 3 5 5 5
46 4 4 5 4 5
47 - 4 5 5 5
48 5 5 5 5 5
|
|
P6_4 |
P6_5 |
P4_1 |
P6_2 |
P4_3 |
Promedio |
|
Experto |
4.0 |
4.0 |
4.45 |
4.54 |
4.63 |
4.32 |
|
Otros |
3.56 |
4 |
4.14 |
4.08 |
4.09 |
3.97 |
|
|
P6_4 |
P6_5 |
P4_1 |
P6_2 |
P4_3 |
Promedio |
|
Experto |
0.75 |
0.75 |
0.86 |
0.88 |
0.9 |
0.83 |
|
Otros |
0.64 |
0.75 |
0.79 |
0.77 |
0.77 |
0.74 |
Según la escala 0-1, la librería agricolae está categorizada como un software de calidad, MUY BUENA, sin considerar la opinión de expertos presentada que también es muy favorable.